Here is my implementation of an in-place quicksort algorithm, an adaptation from this video:
def partition(arr, start, size):
if (size < 2):
return
index = int(math.floor(random.random()*size))
L = start
U = start+size-1
pivot = arr[start+index]
while (L < U):
while arr[L] < pivot:
L = L + 1
while arr[U] > pivot:
U = U - 1
temp = arr[L]
arr[L] = arr[U]
arr[U] = temp
partition(arr, start, L-start)
partition(arr, L+1, size-(L-start)-1)
There seems to be a few implementations of the scanning step where the array (or current portion of the array) is divided into 3 segments: elements lower than the pivot, the pivot, and elements greater than the pivot. I am scanning from the left for elements greater than or equal to the pivot, and from the right for elements less than or equal to the pivot. Once one of each is found, the swap is made, and the loop continues until the left marker is equal to or greater than the right marker. However, there is another method following this diagram that results in less partition steps in many cases. Can someone verify which method is actually more efficient for the quicksort algorithm?

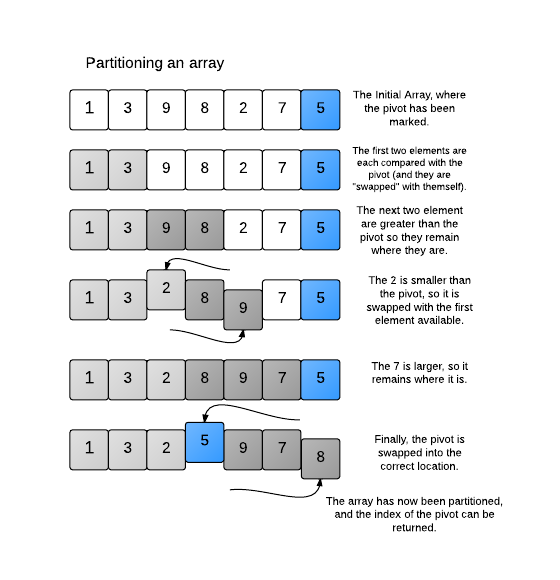{kind=link}
Both the methods you used are basically the same . In the above code
Index is chosen randomly, so it can be first element or the last element. In the link https://s3.amazonaws.com/hr-challenge-images/quick-sort/QuickSortInPlace.png they Initailly take the last element as pivot and Move in same way as you do in the code.
So both methods are same. In your code you randomly select the pivot, In the Image - you state the Pivot.