I am currently trying to learn Tensorflow and have gotten to the point where I need to create some corpus' datasets. I don't have the money to drop for the annotated Gigaword English corpus at LDC so I am looking at creating my own scraper. I have gotten some articles from online, but now want to format them in a way similar to the LDC Gigaword sample here: https://catalog.ldc.upenn.edu/desc/addenda/LDC2012T21.jpg
{kind=link}
I am trying to use the Parsey Mcparseface model to POS tag my input and help me in outputting the multiple xml files. I currently have gotten close to the output I want by using python to modify the conll2tree.py file and and the demo.sh file to allow me to read in my input from a single file. The commandline used is shown at the bottom of this post.
What I am trying to figure out is how to have the model process all files in a directory. My current scraper is written in JavaScript and outputs separate .json files which contain a json object with a title, body, image, etc. I have used sentence boundary detection to separate each sentence with a comma but it seems my input to parsey will need to be an input where each sentence is on a different line. I will modify this in my python script but I still have no idea on how to configure the params below so that I can have it just iterate over each file, read in the content, process and move on to the next file. Is there a way of setting a wildcard for the input param? Or do I need to send each file individually via commandline in my python script? I just assume if there is a way the parsey model or rather SyntexNet can process them in batch, it will probably be quicker.
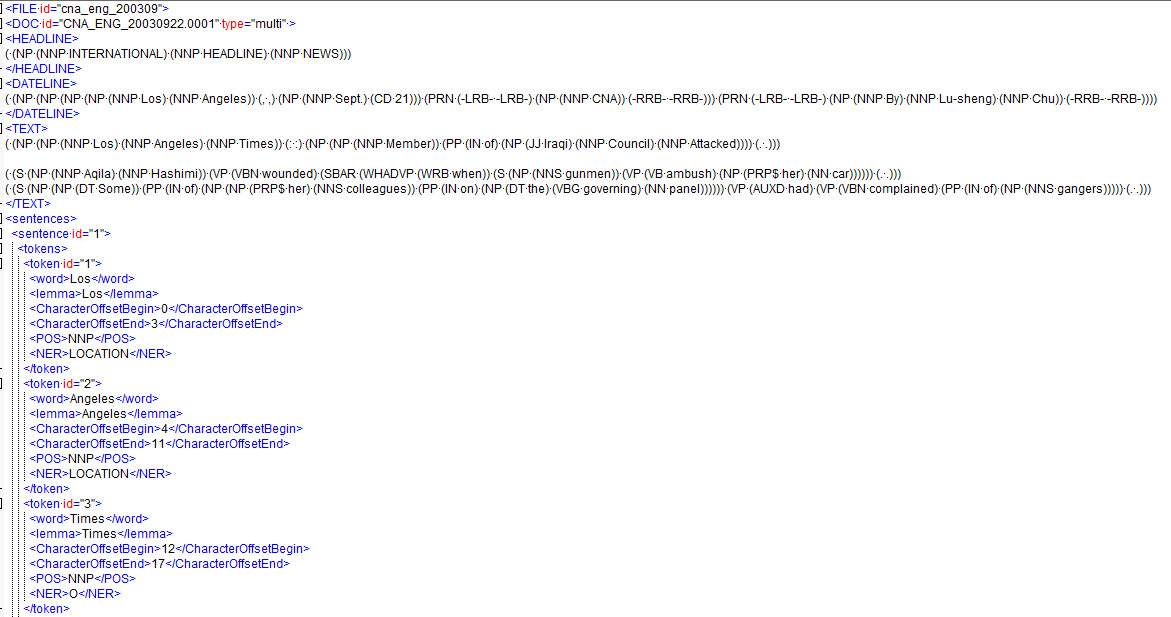
One other question I had is whether or not there is a way to have Parsey Mcparseface output the format as shown in the "headline" of the image above which is like this:
(.(NP.(NNP.INTERNATIONAL).(NNP.HEADLINE).(NNP.NEWS)))
If not, what is this format called so I can look more into how I can go about doing this via code myself? The part that is throwing me off is the prefixed number of NP's (assume noun phrase).
I've managed to extract out the POS tags into a format like the one in the image shown via the sentence tokens, but I'm assuming that as I get deeper into Tensorflow, it will be good to have the formatting they are showing in the headline and textfield tags as well since it shows more of the relationships of the words to each other.
PARSER_EVAL=bazel-bin/syntaxnet/parser_eval
MODEL_DIR=syntaxnet/models/parsey_mcparseface
[[ "$1" == "--conll" ]] && INPUT_FORMAT=stdin-conll || INPUT_FORMAT=stdin
#--input=testin \
#--input=$INPUT_FORMAT \
$PARSER_EVAL \
--input=testin \
--output=stdout-conll \
--hidden_layer_sizes=64 \
--arg_prefix=brain_tagger \
--graph_builder=structured \
--task_context=$MODEL_DIR/context.pbtxt \
--model_path=$MODEL_DIR/tagger-params \
--slim_model \
--batch_size=1024 \
--alsologtostderr \
| \
$PARSER_EVAL \
--input=stdin-conll \
--output=testout \
--hidden_layer_sizes=512,512 \
--arg_prefix=brain_parser \
--graph_builder=structured \
--task_context=$MODEL_DIR/context.pbtxt \
--model_path=$MODEL_DIR/parser-params \
--slim_model \
--batch_size=1024 \
--alsologtostderr \
| \
bazel-bin/syntaxnet/danspos \
--task_context=$MODEL_DIR/context.pbtxt \
--alsologtostderr
I have also added the below entries to the content.pbtxt file:
input {
name: 'testin'
record_format: 'english-text'
Part {
file_pattern: './testinp.txt'
}
}
input {
name: 'testout'
record_format: 'conll-sentence'
Part {
file_pattern: './testoutput.txt'
}
}